How RichRelevance uses Spark
As the global leader in omnichannel personalization, we at RichRelevance take pride in providing the most relevant and innovative customer experience to end users. Every day we deliver over half a billion placement views to more than 50 million unique online shoppers worldwide. A shopper journey in our customers site is recorded as a sequence of Views, Clicks and Purchases which we call a Visit. All this user generated data is recorded in our front-end data centers and saved as Avro logs in HDFS on our backend Hadoop cluster. This valuable user data is used across teams to power our products and services.
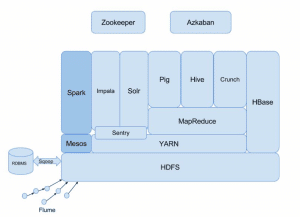
New RichRelevance Big Data Ecosystem
As a company we have a decade long history of big data. Different teams have their own data requirements which involves transforming raw user data in HDFS into specific formats using Hadoop MapReduce jobs. Some of these jobs can take very long to run. As a result teams would have their own data pipelines which were run as per the frequency of their data needs. These different data pipelines have duplicate calculations that need to be managed and maintained independently or data consistency challenges arise.
As the data requirements in the company continued to increase, managing and updating MapReduce jobs written many years ago became a challenge. Additionally, some metrics present across multiple reports began to slowly diverge. Thus, it became important for RichRelevance to consolidate and upgrade jobs into a single, general purpose, high performance data processing framework. The advent of Apache Spark enabled RichRelevance to unify our data pipelines and usher in a new chapter in our growing data needs.
Here’s why we chose Spark:
- RichRelevance’s internal expertise of Scala and functional programming
- Spark jobs are easy to develop and deploy for testing as well as Production deployments
- Spark integrates well with our existing Hadoop Infrastructure
- It is easy to write unit and integration tests during development, we have complete Spark jobs running as part of our test suite
- Advanced Analytics support with MLib and Spark Streaming
- Spark history server helps in detailed analysis of our past runs
- Spark offers inbuilt execution engine that handles coordination and evaluation
- Ability to skip common stages across multiple jobs
- Legacy jobs and data pipelines co-exist in the Hadoop ecosystem while they are being migrated to Spark
- Both Mesos and YARN integration
- Dynamic Memory allocation mechanism that enables the application to give resources back to the cluster if they are no longer used and request them again later when demand increases. This helps us to run multiple applications smoothly on our Spark cluster
Unified Data Pipeline
We run our Spark jobs in 2 stages.
First we group Clicks, Views and Purchases per Shopper across all channels into Visits. Each Visit has detailed information about every product and recommendation seen by a Shopper, items he clicked on, and all purchases made. Visits are saved in Parquet columnar storage format. The Visit structure provides us a good foundation for all the future data transformations.
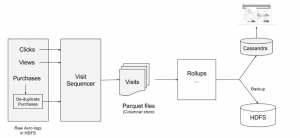
Data Pipeline
The second stage consists of multiple rollups that run in parallel. These jobs output data that is used for various purposes like reporting, data analytics, multivariate tests, inputs to model builds and machine learning algorithms. There are similar calculations and stages across these rollups, so Spark skips stages by fetching already calculated data from cache, thus avoiding re-execution of these stages. The data obtained from these rollups are saved in Cassandra or HDFS depending on the use case of the individual rollup. HDFS also serves as our primary backup of all rolled up data. The metrics stored in Cassandra power data reporting and health checks.
Black Friday weekend and the following holiday season is the busiest time of the year for us. Shoppers generate hundreds of Gigabytes of data every day. In the past daily reporting jobs themselves could take many hours to finish which would delay not just reports but also other MapReduce jobs that are waiting on cluster resources. However, our new Spark data pipeline enables us to run all the above rollups in parallel in one fourth of the time and what’s more is it provides us with more granular data.
Our quest for on-time and accurate data reporting does not end with fast running batch jobs. In future blog posts we will talk about how we handle Real-time reporting at RichRelevance.